
인공지능(AI)이 보편화되면서 기계학습의 한 종류인 딥러닝을 위한 학습에는 GPU를 사용하는 것이 일반화되었습니다. 2021년의 시작과 동시에 사물 인식(Vision) 및 광학 판독(OCR) 프로젝트를 수행하게 되었는데 이 과정에서의 AMD GPU를 활용한 경험을 공유합니다. PlaidML 이라고 하는 강력한 텐서 컴파일러를 사용했습니다.
인공지능 학습이란?
컴퓨터를 활용해 패턴화되지 않은 다양한 실세계의 사물을 인식하는데는 엄청난 양의 데이터를 학습해서 추론하는 과정이 필수적입니다. 요즘 흔히 들리는 기계학습, 딥러닝 등 인공지능과 관련된 일련의 과정들이 모두 최적의 추론을 위한 것입니다. 컴퓨터 공학에서 인공 신경망을 활용하려는 시도는 매우 오래전부터 있어왔습니다. 인공지능에 대해서는 이 글(위키피디아 – 인공지능)을 한번 읽어 보시길 권해드립니다. 간단히 말해 인공지능을 위한 기계 학습은 컴퓨터가 최적의 모델을 찾아가는 시행착오의 과정이라고 이해하시면 됩니다.


기계학습(딥러닝)에는 왜 GPU를 사용할까?
컴퓨터가 학습을 한다는 것은 사람은 상상할 수도 없는 많은 변수와 행렬, 계층(Layer)간 계산을 반복하는 과정입니다. GPU(Graphics Processing Unit)는 원래 그래픽 렌더링에 특화된 연산을 위해 개발된 장치입니다. 우리가 흔히 알고 있는 CPU(Central Processing Unit)와 컴퓨팅의 연산을 담당하는 것은 동일하지만 그 목적과 구조가 완전히 다릅니다. CPU는 정수나 고정소수점 데이터를 많이 사용하는 인터넷 서핑, 문서 작성 등 일상 생활의 작업을 보다 빠르게 수행하도록 설계하는 반면 GPU는 CPU로는 시간이 많이 걸리는 부동 소수점 실수 연산과 벡터연산을 가지는 멀티미디어, 특히 3차원 그래픽과 사운드를 잘 처리하도록 설계됩니다.
조금 더 쉽게 설명해서 CPU는 여러가지 명령을 처리할 수 있지만 병렬 처리에는 약하고, GPU는 수학 계산만 처리하는 대신 병렬 처리에 강점을 가지는 구조입니다. 일반적으로 CPU는 2~6개 정도의 코어만 가지지만, GPU는 수백, 수천개의 코어가 그래픽카드 안에 내장되어 병렬 연산을 수행하게 되는 구조입니다. (대신 GPU는 사칙 연산 외에는 다른 연산은 전혀 못한다고 보면 이해가 쉽습니다. CPU는 범용 칩셋으로 사칙 연산 뿐만 아니라 다양한 확장 명령을 처리할 수 있는 구조이구요.)
3D 게임과 딥러닝
컴퓨터 입장에서 보면 3D게임에 사용되는 연산이 기계학습의 딥러닝에 사용되는 연산과 동일하다고 생각하시면 됩니다. 그래서 기계학습에 GPU를 사용하는 것이고, 3D게임은 수십년간 빠른 랜더링을 위해 엄청난 속도로 발전을 했고 이는 CPU같은 범용칩이 넘볼수 있는 수준을 훨씬 넘어섰습니다. 어찌보면 인공지능은 게임 기술의 발전 덕분에 덕을 본거라고 말할 수도 있을 정도입니다.
오늘 주제를 벗어나 너무 많은 얘기를 해야될 수도 있어서 이 정도에서 정리합니다 ㅎㅎ 요컨대, 기계학습은 행렬 및 부동소수점 연산을 많이 하게 되고 이는 GPU를 통해서 수행하는 것이 훨씬 빠르고 효율적입니다. 잠시 후 소개해드리는 AMD의 Vega64 그래픽카드만 하더라도 3584개의 코어가 내장되어 있습니다. 현재 가장 최신 PC용 CPU인 인텔 i7 10세대 10700k가 8코어 16쓰레드로 구성되어 있으니 그 차이점을 확실히 아시겠죠?
AMD GPU로 기계학습이 가능할까?
일반적으로 인공지능 학습용으로는 NVIDIA 계열의 GPU가 압도적으로 많이 사용되고 있는 것이 현실입니다. NVIDIA가 CUDA라고 하는 최상의 라이브러리를 제공하기 때문이죠. CUDA (Computed Unified Device Architecture)는 NVIDIA에서 개발한 GPU 개발 툴인데 어셈블리 수준의 하드웨어를 이해하지 못하면 개발하기 쉽지가 않습니다. 따라서 범용성을 높이기 위해 High-Level API (cuDNN) 를 제공하고 이를 이용해서 쉽게 GPU의 기능을 개발할 수 있습니다. 또한 cuDNN 을 활용한 다양한 딥러닝 프레임워크들이 이미 나와 있기 때문에 NVIDIA 그래픽 카드만 있으면 비교적 쉽게 딥러닝을 할 수 있는 것이죠. 그렇다면 AMD GPU를 가지고 딥러닝을 할 수 있을까요? 당연히 할 수 있습니다. AMD 자체의 딥러닝 프레임워크도 있을뿐만 아니라 ROCm을 이용해서 제한적인 cuDNN을 사용하기도 합니다. 그러나 텐서플로우, 파이토치 등 대부분의 딥러닝 프레임워크가 이미 cuDNN 기반에서 개발되어서 활용성에 한계가 분명히 있었습니다. 그런데 GPU의 종류와 상관없이 딥러닝을 가능하게 하는 PlaidML이라는 텐서 컴파일러가 그 활용성의 제한을 없애줄 수 있습니다.
PlaidML – Tensor Compiler
저는 이번에 처음 PlaidML을 알게 되었는데 MAC 사용자들에게는 딥러닝을 할 수 있는 유일한(?) 방법이었더군요 ㅎㅎ 홈페이지는 https://plaidml.github.io/plaidml/ 입니다. 홈페이지의 첫 문장에 PlaidML에 대한 설명이 짧고 강력하게 나타나 있습니다.
PlaidML is an advanced and portable tensor compiler for enabling deep learning on laptops, embedded devices, or other devices where the available computing hardware is not well supported or the available software stack contains unpalatable license restrictions.
제일 마음에 들었던 것은 특정 GPU에 종속되지 않고, 다양한 OS를 지원한다는 것이었습니다. AMD GPU를 사용하기 위해 ROCm을 검토하기도 했지만 오직 리눅스에서만 지원되고 펌웨어 변경까지 해야되는 위험이 있어서 포기했었습니다. PlaidML은 추상화의 추상화를 통해 딥러닝의 실행을 가능하게 하며 현재는 Keras, ONNX, 그리고 nGraph를 지원합니다. Keras는 텐서플로우(Tensorflow)를 활용하므로 제가 원하는 딥러닝을 할 수 있었습니다. GPU 드라이버를 설치한 후 OpenCL 1.2 버전만 있으면(대부분 GPU 드라이버 설치시 같이 설치됩니다.) 사용할 준비 끝! Python 환경에서만 작동합니다.
PlaidML 설치 및 실행 준비
아래 명령어로 파이썬 가상환경을 만들고 PlaidML을 설치합니다.
virtualenv plaidml
source plaidml/bin/activate
pip install plaidml-keras plaidbench그 후 PlaidML 셋업을 실행합니다. 딥러닝에 사용할 하드웨어를 선택하는 부분인데, CPU나 GPU를 선택할 수 있습니다. (아래 동영상에서 자세한 내용 확인할 수 있습니다.)
plaidml-setup
최종적으로 벤치마킹을 실행해 봅니다. 아래 동영상에서 전체 과정을 CPU/GPU 비교해서 볼 수 있습니다. 결과적으로는… AMD Vega 64 로 실행한 벤치마킹이 거의 200배 가까이 빠른 속도를 내네요 ㅎㅎ keras mobilenet은 인공지능으로 객체를 인식하는 비젼 신경망입니다.
plaidbench keras mobilenet
PlaidML Keras mobilenet 벤치마킹 결과 – CPU
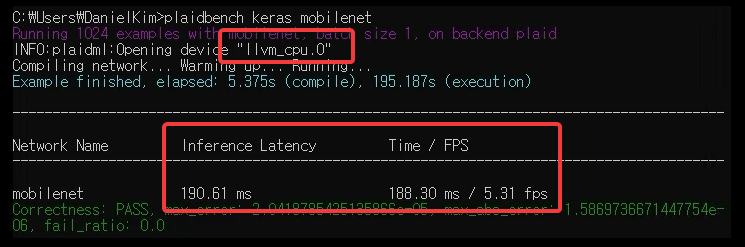
위 그림에서 보듯이 CPU를 선택한 후 실행한 벤치마킹에서는 초당 5.31 프레임을 인식하는 수준으로 전체 배치 수행에 188.30ms 가 소요되었습니다. 추론 지연도 190.61ms로 나온 것을 알 수 있습니다. 참고로 위 벤치마킹을 실행한 CPU는 Intel Xeon(R) CPU E5-2650 v4 @ 2.20GHz입니다.
PlaidML Keras mobilenet 벤치마킹 결과 – GPU
그렇다면 동일한 벤치마킹을 AMD GPU(Vega 64)에서 하면 어떤 결과가 나올까요?

CPU 대비 차이가 보이시나요? ㅎㅎ 초당 710.77 프레임을 인식하면서 배치 수행에 1.41ms만 소요되었습니다. 추론 지연도 8.60ms에 불과하구요. 행렬 및 다차원 연산(미분)을 반복 수행하는 경우에 GPU가 훨씬 효율적이라는 것을 알 수 있습니다.
기존 Python 코드에 PlaidML 적용하는 방법
기존에 텐서플로우를 활용하는 코드에 PlaidML을 적용하는 방법은 아주 간단합니다. 다음과 같이 한줄만 선언해주면 keras가 알아서 PlaidML을 백엔드로 연산을 수행하게 됩니다.
os.environ["KERAS_BACKEND"] = "plaidml.keras.backend"
코드의 상단 선언문 전체는 아래와 같이 구성될겁니다. 정말 간단하게 구현되죠?
#!/usr/bin/env python
import numpy as np
import os
import time
os.environ["KERAS_BACKEND"] = "plaidml.keras.backend"
import keras이상으로 AMD GPU에서 Keras 텐서플로우를 통한 딥러닝 방법을 알아봤습니다. 위와 같이 PlaidML을 이용하면 AMD GPU 뿐만 아니라 인텔 그래픽, CPU 등으로도 딥러닝이 가능하게 됩니다. 그렇지만 작업 효율성을 위해서는 GPU를 선택하는게 좋겠죠? ^^
Tip – 실제 AMD GPU 작동 영상
AMD로 Keras 성공에 기뻐서 케이스 열고 한번 찍어봤습니다 ㅎㅎ Vega 64가 열심히 반복작업을 하고 있는게 보이시죠? 화면에 나오듯이 아직 여러 개의 GPU를 동시 실행하는 것이 지원되지 않습니다… NVIDIA도 완벽히 같은 GPU가 아니면 지원되지 않는 것 보면 쉽지는 않을 것으로 판단됩니다. 참고하세요~
- https://github.com/plaidml/plaidml/issues/1199 (PlaidML MultiGPU 사용에 관한 답변)
- 개발진의 답변 중에 Keras를 통하지 않고 순수 Tensorflow도 조만간 지원할 것으로 보이네요. 기대됩니다!